
De afgelopen periode is er intensief gewerkt aan de basis van een nieuw TrueCare, ons communicatiesysteem voor alle services en support die True biedt. We hadden namelijk een flinke uitdaging: legacy moest samengevoegd worden tot één nieuwe interface. Al snel wisten we dat een microservice architectuur ons zou helpen in de transitie naar één TrueCare. In dit artikel deel ik, Peter van Kleef (Project Manager & Product Owner van TrueCare) de inzichten van het Development-team.
De aanleiding voor TrueCare 2.0
Het afgelopen jaar vond de rebranding van True plaats. Hiermee zijn drie bedrijven (True, Open for Support en Multrix) samengevoegd naar één website en twee labels: True Webspace en True Workspace.
Als onderdeel van de samensmelting is er ook hard gewerkt aan het samenbrengen van processen en systemen in TrueCare. TrueCare is ons beheerportaal waarmee klanten inzicht krijgen in de gekochte producten, de prestaties van webservers en de communicatie met onze servicedesk.
Daarbij hadden we uiteraard een groter doel voor ogen; één TrueCare voor alle klanten – ongeacht de diensten en producten die afgenomen worden.
In relatief korte tijd is het Development-team hard aan de slag gegaan om de bestaande systemen zo goed mogelijk aan elkaar te koppelen voor onze gebruikers. Dat ging echter niet geheel zonder de nodige uitdagingen.
8 x uitdagingen van TrueCare 2.0
Bij het samenvoegen van diverse processen, code en systemen kwamen we de volgende uitdagingen tegen:
Legacy code. Ieder bedrijf dat al wat langer bestaat heeft te maken met ‘legacy code’. Zo ook True. Deze code was in onze glorieuze begindagen geschreven in oude frameworks en met toepassing van oude methodieken. Die code voldeed niet langer aan de huidige maatstaven en kwaliteitseisen.
Architectuur van applicaties. De toepassing van die oude methodieken heeft er onder andere toe geleid dat de applicaties groot (lees: monolitisch) opgebouwd zijn en daardoor veel code bevatten en grote databases als achterliggende bronnen gebruiken. Daarnaast bevatten die applicaties veel complexe logica voor veel verschillende businesscases.
Kleine aanpassing = grote gevolgen. Die complexe logica, in combinatie met de afhankelijkheden die in de code zitten, leidt er vervolgens toe dat een kleine aanpassing in één deel tot problemen in andere delen van de applicatie kan leiden.
Nóg meer logica. Omdat veel functionaliteiten, in de basis, gelijkend zijn voor klanten en medewerkers zijn enkele van de oude applicaties volgens dat gedachtegoed opgebouwd; die applicaties bedienen zowel klanten als medewerkers. Daardoor wordt nog meer logica in de applicaties gebouwd en introduceer je potentiële beveiligingsrisico’s.
Verschillende applicaties. Door het samengaan van de verschillende ondernemingen ontstond nóg een uitdaging; verschillende applicaties en systemen die aan elkaar gekoppeld moesten worden; deze systemen en applicaties zijn uiteraard op andere manieren gebouwd, volgens andere methodieken en veelal in verschillende (versies van) frameworks.
En nog een paar uitdagingen:
- Het is bijna onmogelijk om verschillende onderdelen van de applicatie op een goede manier als API beschikbaar te maken.
- Het updaten van PHP of zelfs het framework is bijna ondoenlijk omdat de code zo complex is.
- Het is voor nieuwe developers moeilijk om kennis op te doen van de monolitische applicatiecode omdat deze vaak verouderd en/of complex is.
Voor iedere uitdaging een oplossing
Toen we ongeveer twee jaar geleden, her en der verspreid, gesprekken voerden over de uitdagingen waar we destijds al tegen aan liepen – bijvoorbeeld onder het genot van een biertje op de vaste vrijdagmiddagborrel – speelden sommige van deze uitdagingen nog geen rol van betekenis. Wel kwam al snel de term ’microservices’ op.
Microservices?
Na wat leeswerk werd duidelijk dat er veel voordelen zaten aan deze andere gedachtegang over het opbouwen van applicaties. In het plaatje hieronder is schematisch het verschil tussen een monolitische architectuur en een microservice architectuur weergegeven.
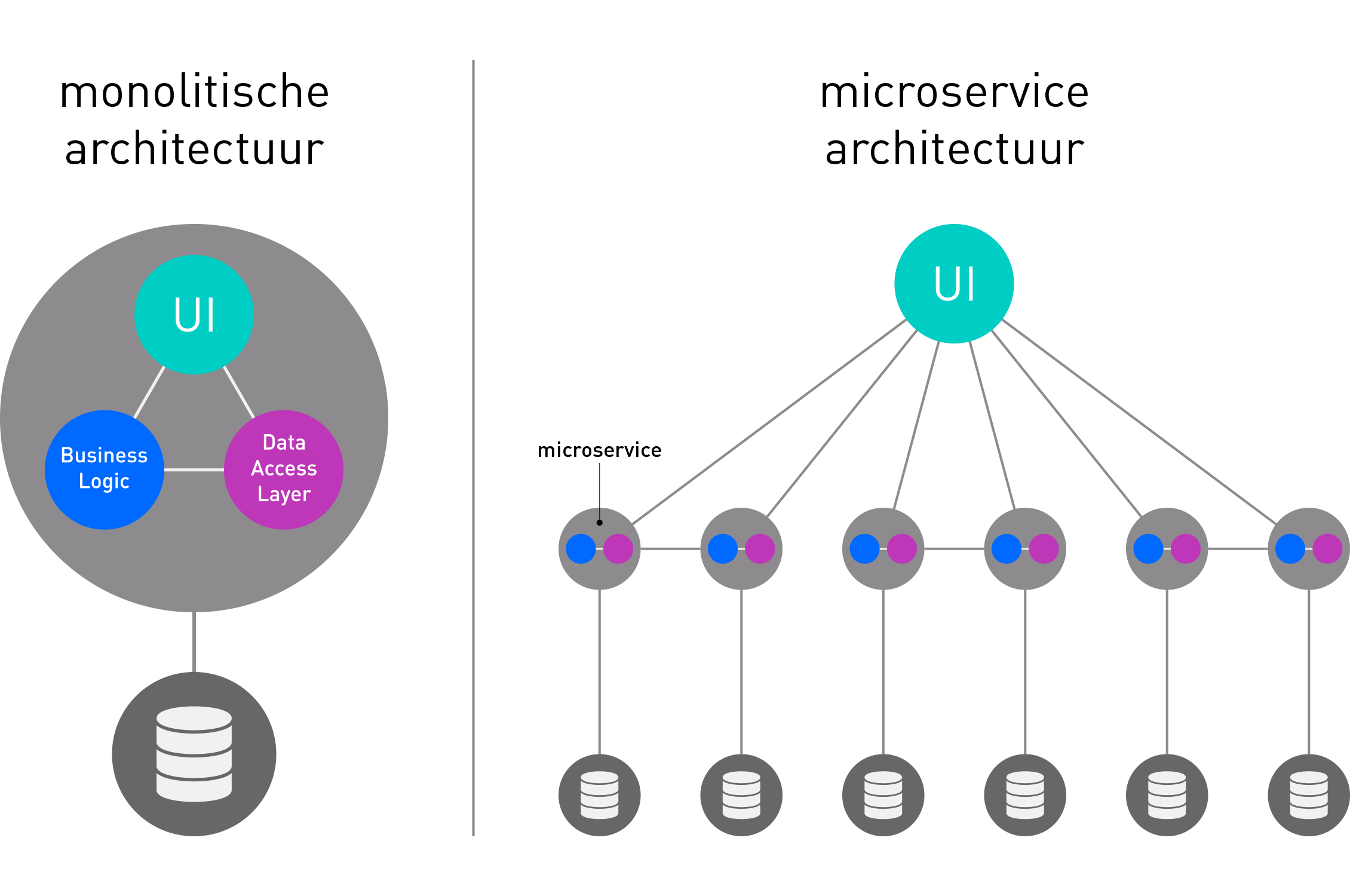
Kort samengevat betekent dat het volgende:
In een microservice architectuur splits je een monolitische applicatie op in verschillende kleine ‘services’ met een specifieke scope voor een specifiek doeleinde. Al deze kleine services zijn API’s die ook onderling kunnen communiceren om op deze wijze data uit te wisselen en/of aan te vullen. Om het geheel aan elkaar te knopen kun je een (of meerdere!) ’front-end’ microservice(s) ontwikkelen, welke (al) deze API’s consumeert.
Microservices, als het principe goed toegepast is, passen als blokjes in een ‘blokkendoos’ in elkaar; ze zijn stapelbaar, schaalbaar, uitbreidbaar en kunnen gedupliceerd worden.
De effecten van microservices
(Business)logica wordt opgesplitst in kleinere onderdelen. De complexiteit per applicatie wordt geminimaliseerd en heeft iedere applicatie eigen verantwoordelijkheden.
Vervangen van onderdelen, los van elkaar, wordt eenvoudiger. Ook aanpassingen kunnen worden gedaan zonder dat dat verregaande gevolgen heeft omdat iedere microservice andere verantwoordelijkheden heeft.
Updaten kan wederom gefaseerd gedaan worden. En brengt relatief minder complexiteit met zich mee dan wanneer dat bij een applicatie gedaan moet worden die volgens de monolitische architectuur gebouwd is.
Uitfaseren van (oude) microservices wordt eenvoudig gemaakt. Omdat een oude en nieuwe versie naast elkaar in werking kunnen blijven, zodat goed getest kan worden en gemigreerd kan worden naar de nieuwe omgeving. Diezelfde denkwijze kan ingezet worden om, gefaseerd, de oude monolitische applicaties te vervangen met nieuwe microservices.
Nadelen microservices?
Er zijn echter ook nadelen te noemen voor deze microservice architectuur;
- Je moet immers voor iedere losse microservice boilerplate opbouwen en eventuele CI/CD inregelen – dat is nogal wat overhead.
- Daarnaast is het belangrijk dat er goed na wordt gedacht over hoe de verschillende microservices met elkaar communiceren
- Tevens is er een omgeving (of meerdere omgevingen als we het OTAP-principe in acht nemen) nodig waarop het publiceren van deze microservices mogelijk wordt.
Waar een wil is, is een weg
Na verschillende malen overleg en aangepaste voorstellen is er uiteindelijk een plan op tafel gekomen om de bestaande applicaties incrementeel om te bouwen naar microservices.
- Onderdeel van dat plan was dat er met een vaste stack (frameworks) gewerkt zou gaan worden vanaf heden.
- Ook zou er ‘Event Sourcing’ toegepast worden en werd er een vast stramien bedacht voor de communicatie tussen de verschillende microservices.
- Een ander onderdeel was dat er voor die vaste stack een standaard ontwikkeld zou worden, genaamd ‘AppSkeleton’.
- De AppSkeleton bevat de basis die benodigd is voor iedere nieuwe microservice (Event Sourcing, basis API-structuur, basis boilerplate en vooraf bepaalde CI/CD parameters).
De front-end was op dat moment nog een vraagstuk dat op een later moment ingevuld zou worden.
Dichter bij TrueCare 2.0
Nadat we één True geworden zijn was het samenvoegen van de TrueCare-experience een logische vervolgstap. Er is in dit artikel ingegaan op welke problematiek we daarbij tegenkwamen en vooral wat ons plan was om deze problematiek te verhelpen.
In het volgende artikel zal worden ingegaan op hoe we het plan in werking hebben gezet en hoe we invulling aan het volledige project gegeven hebben als Development-team. Daarbij wordt ook dieper ingegaan op sommige van de in dit artikel genoemde principes (‘Event Sourcing’, de stack, de ‘AppSkeleton’ en de front-end)









